¿Quién no ha realizado algún proyecto y ha necesitado información de prueba?
Mediante el web scraping, esta tarea resulta trivial, y no te preocupes, no vas a escribir todo a mano.
Para comenzar, utilizaré el mismo ejemplo de un post anterior: Webscraping básico con Python - I
En dicho post realizamos scraping al website de Hacker News
En esta ocasión realizaremos algo similar pero solo con la librería estándar de python para enfocarlo de otra manera:
Paso #1: Consultar a la url
Utilizamos la librería urllib de python para consultar el enlace:
::python
from urllib.request import urlopen
with urlopen('https://news.ycombinator.com/') as f:
pass
Paso #2: Extraemos los títulos
Al igual que en el post que escribí antes, observamos en el html de Hacker News

y notamos que el título de cada noticia tienen la forma de:
class="storylink">TÍTULO</a>
con ello podemos hacer uso de las expresiones regulares para extraer los bloques similares.
Nota: No olvidemos que tenemos que convertir la salida de urlopen para poder leerla como string.
::python
from urllib.request import urlopen
import re
with urlopen('https://news.ycombinator.com/') as f:
all_titles = re.findall(r'class="storylink">(.*?)<', f.read().decode('utf-8'))
Paso 3: El gran final, generar las sentencias SQL
Las sentencias INSERT tienen la siguiente forma:
INSERT INTO "nombre_tabla" ("columna1", "columna2", ...);
organizando nuestro código para producir dicha salida, tendríamos:
::python
from urllib.request import urlopen
import re
with urlopen('https://news.ycombinator.com/') as f:
all_titles = re.findall(r'class="storylink">(.*?)<', f.read().decode('utf-8'))
for title in all_titles:
print (f'insert into Titles values ("{title}");')
Y al ejecutar dicho código en la consola tendríamos una salida similar a:
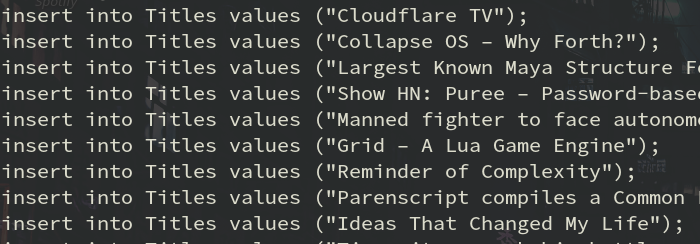
Ejemplo extra: obteniendo noticias del diario "El Comercio"
Tomando como base la página de noticias de Política de "El Comercio", podríamos realizarlo con:
::python
import re
from urllib.request import urlopen
with urlopen('https://elcomercio.pe/politica/') as f:
all_titles = re.findall(r'class="story-item__title block overflow-hidden primary-font line-h-xs mt-10" href="([\w/-]*?)">(.*?)</a>', f.read().decode('utf-8'))
for url, title in all_titles:
print(title)
De este modo obtenemos los títulos de las últimas 50 noticias:
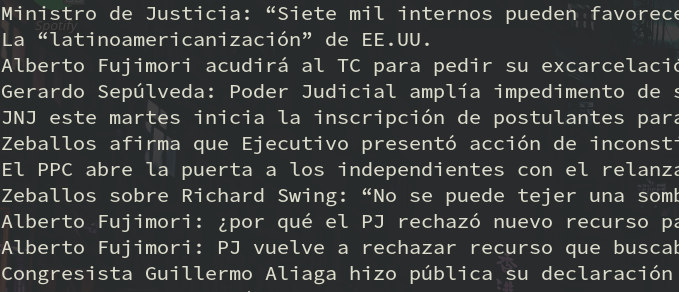
Notas finales
-
No debemos olvidar que siempre que realicemos webscraping tengamos en cuenta los factores legales: propiedad intelectual, cuidarse de no agotar al servidor con muchas consultas simultáneas, sensibilidad de la información, etc.
-
Podemos mejorar nuestro código mediante el uso de librerías como: requests, beautifulsoup, faster_than_requests u otras.
Comentarios !
comments powered by Disqus