¿Qué es el web scraping?
Es una técnica utilizada mediante programas de software para extraer información de sitios web. Usualmente, estos programas simulan la navegación de un humano en la World Wide Web ya sea utilizando el protocolo HTTP manualmente, o incrustando un navegador en una aplicación.1
Entre algunos tipos de contenidos que podríamos necesitar extraer tenemos a:
- listados de noticias o empleos
- lista de productos, sus imágenes y precios
- relación de libros
- otros
A modo de ejemplo, extraeré contenido de la primera página de Hacker News.
Requerimientos
- requests: para realizar la descarga del contenido del website
- beautifulsoup4: nos permite navegar en el contenido extraido de forma sencilla
Los instalamos mediante pip:
pip install requests beautifulsoup4
Obtenemos el contenido en formato html de la página a consultar
::python
import requests
url = 'https://news.ycombinator.com/'
content = requests.get(url)
print(content.text)
Utilizamos beautifulsoup para navegar a través del código html
Ahora que tenemos el contenido, podemos por ejemplo, intentar listar los títulos de los 30 post que hacker news nos muestra en la primera página.
Notemos que podemos usar selectores css con beautifulsoup, por lo que es recomendable conocer los mismos, como:
- selectores por id: "#boton_enviar"
- selectores por clase: ".lista_de_items"
- selectores de tipo: "button"
- selectores de atributo: "[attr=value]"
Podemos darles un repaso en la documentación de Mozilla Developer Network
Entonces, si utilizamos el inspector de elementos de chrome o firefox en la web de Hacker News podemos observar algo como:
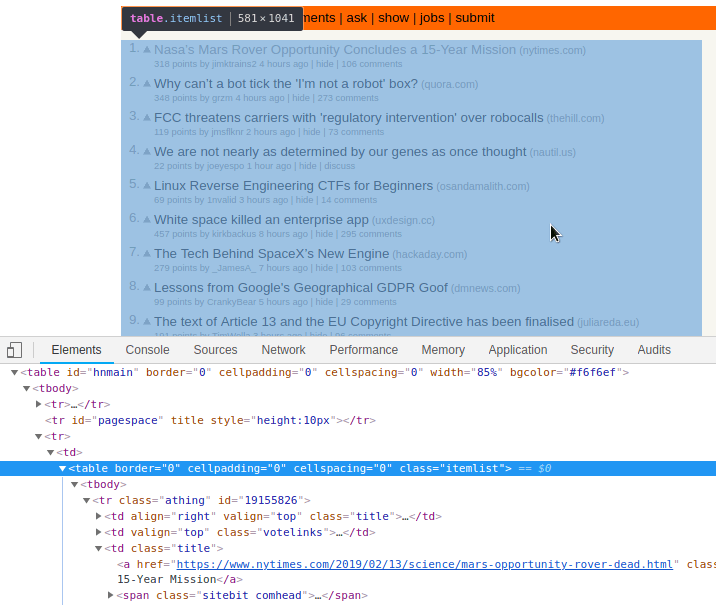
Donde vemos que el contenedor de la lista de historias tiene la clase "itemlist".
Y cada item de la tabla tiene la clase "storylink"
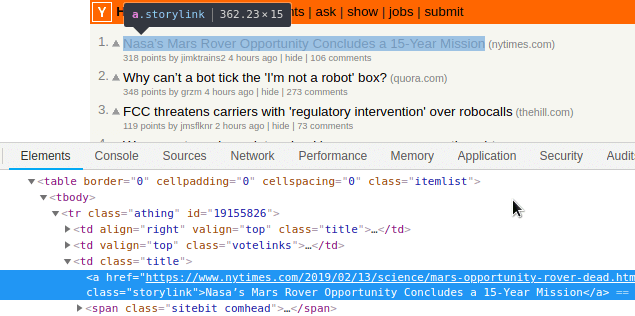
Entonces nuestro código para iterar sobre cada elemento quedaría como:
::python
import requests
from bs4 import BeautifulSoup
url = 'https://news.ycombinator.com/'
content = requests.get(url).text
print(content)
soup = BeautifulSoup(content, 'html.parser')
posts = soup.select('.itemlist .storylink')
print(len(posts), 'posts')
for post in posts:
print(post.text)
Asi obtendremos el listado de títulos
30 posts
I Bought a House with Solar Panels
JP Morgan Unveils USD-Backed Cryptocurrency for B2B Payments
Amazon Pulls Out of Planned New York City Campus
You don't need to quit your job to make
A Distracted Walk with Fundamental Analysis
Extraer el enlace de cada post
Si quisiéramos avanzar un poco más podríamos obtener los enlaces mediante el método "get":
::python
for post in posts:
print(post.text)
print(post.get('href')
Notemos que podemos interactuar con el contenido de muchas maneras, las cuales se pueden revisar en la documentación de beautifulsoup
Otras consideraciones
Al realizar webscraping debemos tener en cuenta puntos como:
-
La legalidad: no siempre que algo esté publicado en internet significa que podamos copiarlo.
-
Sobrecarga del servidor: hay que tener cuidado con realizar demasiadas solicitudes al servidor al que queremos consultar, ya que no queremos realizar un ataque DDOS e inhabilitar el website.
-
No siempre los contenidos están en el formato que deseamos, a veces tenemos que utilizar expresiones regulares para extraer solo lo relevante.
-
Protección anti-webscraping: algunas webs tienen medidas como captchas, o bloqueos por IP al exceder cierto número de solicitudes.
Eso es todo.. por ahora
De momento sirve a modo de introducción. En otra oportunidad daré algún ejemplo más complejo.
-
Definición según wikipedia ↩
Comentarios !
comments powered by Disqus